

 A Multi-Faceted Approach to Reliable Collection and Handling of Supervisory Control and Data Acquisition (SCADA) Data
A Multi-Faceted Approach to Reliable Collection and Handling of Supervisory Control and Data Acquisition (SCADA) Data

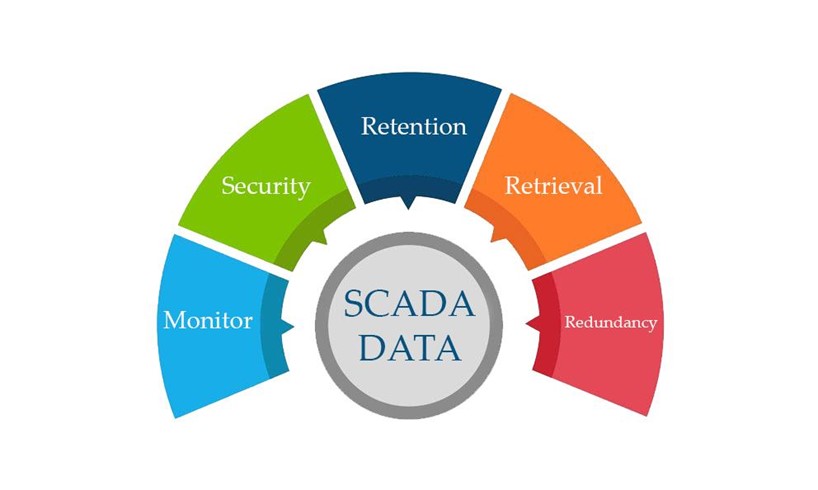
We collect a lot of data in the water/wastewater industry. Data is required for regulations, engineering, operations, and process improvement; we need to be able to collect, store, and retrieve quality data securely and reliably. Our methods used to collect this data range from random sticky notes collected by operators to voluminous databases filled with data collected from Internet of Things (IoT) devices. When we talk about data loss prevention, we are generally assuming that the data has already been collected and stored, and in the information technology (IT) world, this is mostly true. In the operational technology (OT) world, using the MSDR3 (Monitor, Security, Data Retention, Retrieval and Redundancy) method, data loss prevention begins with the instruments that are providing the data and the operators that maintain them, ending with our data deletion policies.
By leveraging existing OT systems combined with IT systems and procedures, we can ensure that the data we are working with will help lead to the desired outcomes. By focusing on maintaining data quality, we can utilize our existing security, network, and controls systems towards achieving that goal and filling in the gaps where they exist. With the convergence of IT/OT technologies, skills, and practices, we can form a single method that when implemented allows us to maintain IT/OT segmentation while ensuring we collect and deliver quality and reliable data.
“We are entering a new world where data may be more important than software.” - Tim O'Reilly
Introduction
With the rise in the use of industrial automation and artificial intelligence (AI) in manufacturing and production, increased regulations in data collection and retention, rapid developments in instrumentation and controls, as well as a marked increase in the need for secure data transmission, there is a need for evolution regarding our methods of data handling. We need to update the ways data sources are monitored, data is validated, verified, stored, and retrieval is optimized. Between 2010-2020, the creation, capturing, and consumption of data went up by a massive 5000%, making the need for cohesive policies and strategies more important than ever before.
No more are manual readings written on a spreadsheet on a clipboard. Replaced by instrumentation, programmable logic controllers (PLCs), and databases, we have gained the ability to reduce human error by 100%. Even with the reduction of human error, there is still the potential for error. As systems become increasingly more complex, they introduce a slew of high-level issues regarding how to store, handle, and deliver the exceedingly large amount of digital data reliably and securely.
The potential consequences of data loss or inaccurate data in reference to regulations can range from multi-million dollar fines to possible criminal charges. When using data for operational design and planning, inaccurate data can lead to multi-million dollar projects failing to achieve the desired outcomes, introducing a threat to life, limb, health, and other operational consequences.
Knowledge in multiple technological fields, including network architecture and management; database management and scripting; security policy; instrumentation and controls; PLC; human-machine interface (HMI) development; and basic IT skills are valuable tools when developing our data handling policies. As discussed later in this article, IT/OT segmentation is crucial, but IT skills are necessary. While there may be mention of specific products or applications, it is by no means an endorsement but a demonstration of real-world scenarios. The practices covered here do not require any application, program, or equipment and should be applied regardless of your preferred vendors or architecture.
The methods outlined in this article have been broken up into three principal components. Monitoring, Security, and Data Handling, with the latter subdivided into three categories of data handling (Retention, Retrieval and Redundancy). While an argument could be made for placing security above monitoring, and in a controls philosophy (safety through security) or in the IT realm where there is the possibility of confidential data exposure (security through obfuscation) it would make sense, here we are talking about SCADA data and data handling specifically. So, the argument is that without reliable data, the need for secure data ceases to exist. First, we need to make sure the data is reliable and usable.
“Plans are useless, but planning is indispensable.” - Dwight D. Eisenhower
MONITOR
The question then becomes, “How do we make sure our data is reliable and useful?”
Which elements of our system can we monitor to ensure the data we are getting meets the usability standards as we have defined for our needs? What is the primary source of our data? In the industrial world, we could, and should, start with our edge devices; the instrumentation and equipment that are providing the values. While there are many measures and methods to determine the reliability of instrumentation and equipment, one of the most dependable methods would be a normalized value range and average rate of change, or plausibility checking.
Let's take a PH meter for example. The generally accepted known value range for PH is 0-14. Monitoring this value, we can determine that anything outside of this range is no longer reliable data and could indicate an issue with either the transducer, transmitter, or any intermediary devices between the data source and the collection system. We can also trend the rate of change of a particular value and alert on an abnormal rate of change. We can use several methods to make sure our edge devices are maintaining reliable connections and providing valuable data. Using manufacture-equipped fail and range functions gives us a device-level opportunity to monitor.
Along with monitoring the physical connection, we also need to make sure the devices providing the values are providing reliable data. This typically involves calibration procedures and standard operating procedures (SOPs) regarding general maintenance, upkeep, and the security of the devices themselves. The methods used for these procedures vary from device to device, but are just as important as the physical connection, and thus should be monitored and tracked diligently.
Once we have defined methods for monitoring our raw data sources and determined that the data we are receiving is reliable and useful, we need to make sure the methods in which we are transferring the data to our database remains reliable and make sure we are collecting data at usable or required intervals. This could include monitoring the PLC or distributed control system (DCS) controller cycle time as well as the uptime.
This allows us to catch hardware interruptions before they can affect the data itself. We can use plausibility checking to give us program and controller level monitoring. We can monitor the log times of the most current data as well as time differentials between specific logged data to determine proper intervals. Our transfer methods include everything from the physical connection to our database server (e.g., PLC to SCADA network to the programmatic methods we use to transfer the data to the database whether it is a direct data entry [DDE] or open database connectivity [ODBC] data connection, an open platform communications [OPC] or OPC unified architecture [UA] interface, a data logging function built into SCADA software, a message queueing telemetry transport [MQTT] broker, or custom queries running directly from a data server).
While the methods to monitor our data connections will vary, the basic idea is to make sure that the services driving the data transfer are functioning as required. As in, the connections through which we are transferring the data are maintaining reliability (to be discussed more in-depth later), and that we are logging the data at the required intervals. The methods we use to achieve these goals will vary widely from system to system. With the use of custom scripting (PowerShell, Python, Visual Basic for Applications [VBA], etc.) to monitor time differentials in logged data as well as the connection status of the database itself, we can ensure a high level of reliability.
We can also use software and custom scripts to monitor connections to the network interfaces as well as specific running services (e.g., SQL server agent, automated jobs, or data transfer executables). Depending on the system you are using, application and security event logs can provide valuable information and can be monitored. We should monitor the size of our database files to keep them within an acceptable range and reduce the potential for disruptions in data collection. We should have the ability to notify the relevant people if a script fails to run as scheduled, returns incorrect or invalid values, or the time differentials are out of range. This would typically be handled with email and text message capabilities as well as potentially alerting the operators through the SCADA or HMI alarming system when possible.
To summarize, monitoring is of utmost importance, as without reliable, quality data the rest is irrelevant. The use of our data relies solely on the quality of our data, so organizations should continually pursue oversight and verification of data quality.
Some of the elements of the monitoring component include:
- Data Sources: The instrumentation and equipment providing the data (physical connection as well as calibration and maintenance procedures and outcomes).
- Database: The transfer methods of the data to the database (connection status, data transfer services, file size, success status of jobs, etc.).
- Data Intervals: The intervals at which we log the data points.
The overall goal is to monitor many of the potential points of failure from the data source to the database itself. Using manufacturer-provided fail and range functions gives us a device-level opportunity for monitoring, while deep packet inspection gives us a network-level opportunity, and plausibility checking gives us program and controller level monitoring. Once we are certain that we are obtaining reliable and valuable data, the next step is to secure the data and prevent data loss or corruption.
“Everyone’s got a plan until they get hit.” - Mike Tyson
SECURITY
While the network element of the security component could constitute a section of its own, networking and security have intersected to a point that it is prudent we include them together. With the convergence of IT/OT networks necessary for businesses to keep up with production and reach their goals, we need to advance our strategies for securing not only our data, but the data sources themselves. We need to be able to detect, track down, and eliminate any anomalous behavior in a timely manner before it can influence our system.
The rise of the Fourth Industrial Revolution, colloquially known as “Industry 4.0,” has caused industries to integrate a variety of digital solutions to networks in the form of “smart” devices and instrumentation to remain competitive, maintain compliance with regulations, and improve quality of service. These devices, while making data collection more efficient and available, also requires us to evaluate the interconnectedness of our networks and refine our methods of network segmentation. What was traditionally an air-gapped network is now connected to IT networks along with new technologies, creating the IoT and subsequently the Industrial Internet of Things (IIoT), which consequently has introduced a myriad of cybersecurity issues.
While servers, database technologies, networking devices, and data analytics typically belong in the realm of IT, IIoT devices have allowed us to integrate a wide assortment of sensors for gathering real-world conditions. Devices like temperature, pressure, and chemical composition sensors as well as actuators that translate digital commands and instructions into physical actions (such as controlling valves and moving mechanisms) now provide a wide array of data that we can utilize in day-to-day operations as well as in design and engineering. Integrating IoT devices into our network and operations has required that we dive headfirst into the world of IT while maintaining the safety and availability of our systems.
While IT security would generally prioritize confidentiality, and OT would prioritize safety, here we focus on the security of our data to prevent potential loss or corruption. The type of data, as well as the treatment of data, differs significantly between IT and OT. Much of the data that IT deals with requires security through encryption (security through obscurity) due to its sensitive nature (such as passwords, HIPAA requirements, social security numbers, etc.). However, a breach of IT data typically will not affect real-world process outcomes or threaten life and limb. While OT data typically would not require as strong of encryption (unless the data is of a proprietary nature in the case of pharmaceuticals or manufacturing procedures), our data sources require more security, rather than encryption, than that of IT data, as OT data controls the process and outcomes of the physical world.
With a large amount of our instrumentation and controls connected to our network, we should keep in mind that many of these devices have configuration capabilities and interfaces that provide a potential exploit into our system. When commissioning such devices, the first thing we should do is change the default username, password, and network settings. This allows us to reduce the possibility of a security breach and gives us a device level opportunity to protect the integrity of our data and device configuration.
Ideally, in a new system, you can segment your IT and OT networks. This is important for a variety of reasons, many of which would constitute its own article (and much has been written on it). For the sake of brevity, as the security component has the potential to get very complex (especially if segmentation was not taken into consideration while designing the system), much of what this article will focus on will involve network security and encryption, as that will be the primary source of protection for our data.
While there are numerous network configurations, the most used in industrial settings are flat networks, firewall rules, dual-home host, and remote access servers. Realistically, not all of these methods provide reliable security or segmentation.
- Flat networks provide almost no security to your OT network, as there is no segmentation. Protecting your OT network is essential to securing data.
- Firewall rules (screened host firewalls), while providing no physical segmentation, at least attempt to limit access to your network, though still not sufficient on its own.
- A dual-homed host system provides almost complete segmentation (save for the dual-homed system) of your IT and OT networks by adding a second network interface. The dual-homed host with firewall (screened subnet firewall with demilitarized zone [DMZ]) adds an extra layer of security to a dual-homed system.
- A remote access server (RAS) provides complete segmentation by using a single workstation through a remote access protocol (commonly known as a remote desktop protocol [RDP]).
While a flat network design can allow us to reduce cost in design and infrastructure by connecting everything to a single switch, we do so at the cost of increased security risk.
 A screened host firewall combines a packet-filtering router with a discrete firewall such as an application proxy server. The router screens the packet before it gets to the internal network; this also allows it to minimize the traffic and network load on the internal proxy. The application proxy receives the requests intended for the server, inspects application layer protocols such as hypertext transfer protocol (HTTP) or hypertext transfer protocol secure (HTTPS), and performs the requested services. This bastion host is frequently a target for external attacks and should be thoroughly secured.
A screened host firewall combines a packet-filtering router with a discrete firewall such as an application proxy server. The router screens the packet before it gets to the internal network; this also allows it to minimize the traffic and network load on the internal proxy. The application proxy receives the requests intended for the server, inspects application layer protocols such as hypertext transfer protocol (HTTP) or hypertext transfer protocol secure (HTTPS), and performs the requested services. This bastion host is frequently a target for external attacks and should be thoroughly secured.
 A dual-homed host architecture is built around the dual-homed host computer or server. This system has at least two network interfaces. We could use this host to route data between the network interfaces as it is capable of routing internet protocol (IP) packets from one network to another. However, when we implement a dual-homed host type of firewall architecture, we disable this routing function. Routing IP packets between these two networks defeats the purpose of the dual-homed system. Anything on the OT side of the firewall can communicate with the dual-homed host, and systems on the IT side of the firewall can communicate with the dual-homed host. However, these systems can't communicate directly with each other as IP traffic between them is completely blocked.
A dual-homed host architecture is built around the dual-homed host computer or server. This system has at least two network interfaces. We could use this host to route data between the network interfaces as it is capable of routing internet protocol (IP) packets from one network to another. However, when we implement a dual-homed host type of firewall architecture, we disable this routing function. Routing IP packets between these two networks defeats the purpose of the dual-homed system. Anything on the OT side of the firewall can communicate with the dual-homed host, and systems on the IT side of the firewall can communicate with the dual-homed host. However, these systems can't communicate directly with each other as IP traffic between them is completely blocked.
 A screened subnet firewall with a DMZ is widely used and implemented in corporate and industrial networks. Screened subnet firewalls with a DMZ make use of DMZ and are a combination of dual-homed gateways and screened host firewalls.
A screened subnet firewall with a DMZ is widely used and implemented in corporate and industrial networks. Screened subnet firewalls with a DMZ make use of DMZ and are a combination of dual-homed gateways and screened host firewalls.
A screened subnet firewall network architecture has three components:
- The first component acts as a public interface and connects to the outside network.
- The second component is a middle zone called a demilitarized zone (DMZ), which acts as a buffer between outside network and OT network components.
- The final component connects to an intranet or other local architecture.
The use of an additional “layer” and other aspects of the screened subnet firewall makes it a viable choice for many high-traffic or high-speed traffic sites. Screened subnet firewalls also help with throughput and flexibility.
 A RAS exists in the OT environment and allows a remotely connected user to perform administration or operation functions using a secure protocol (such as an RDP) from the IT environment. We can then allow the user to access operator workstations or other assets in the OT environment. The IT-side firewall should be configured to allow inbound access from approved IT assets (e.g., a secured administrator workstation) to the jump box only through the approved protocol port. We can maximize the security of the jump box by taking hardening precautions (e.g., disabling unnecessary protocols or services, not storing secure shell [SSH] private keys on it, configuring internal hosts, etc.).
A RAS exists in the OT environment and allows a remotely connected user to perform administration or operation functions using a secure protocol (such as an RDP) from the IT environment. We can then allow the user to access operator workstations or other assets in the OT environment. The IT-side firewall should be configured to allow inbound access from approved IT assets (e.g., a secured administrator workstation) to the jump box only through the approved protocol port. We can maximize the security of the jump box by taking hardening precautions (e.g., disabling unnecessary protocols or services, not storing secure shell [SSH] private keys on it, configuring internal hosts, etc.).
 When we segment our OT network from IT, not only do we add a layer of security and minimize the potential for external actors to affect our ability to collect and retain data, but we also reduce the amount of traffic on our network which allows us to log data at a rate that may not be feasible among the traffic of IT networks. With the introduction of these new devices and technologies, companies have started producing security devices specifically geared toward protecting OT assets (e.g., Hirschmann Xenon Tofino industrial firewall, Darktrace for OT, XONA systems, etc.). While traditional firewalls may protect your network and aid in segmentation, they are not designed for the types of threats we face in OT control systems or industrial threats. New devices along with new communication protocols like Distributed Network Protocol 3 (DNP3) are being developed specifically for communications between various types of data acquisition and control equipment. They are beginning to play a crucial role in SCADA applications by offering more robust, efficient, interoperable, and secure communications.
When we segment our OT network from IT, not only do we add a layer of security and minimize the potential for external actors to affect our ability to collect and retain data, but we also reduce the amount of traffic on our network which allows us to log data at a rate that may not be feasible among the traffic of IT networks. With the introduction of these new devices and technologies, companies have started producing security devices specifically geared toward protecting OT assets (e.g., Hirschmann Xenon Tofino industrial firewall, Darktrace for OT, XONA systems, etc.). While traditional firewalls may protect your network and aid in segmentation, they are not designed for the types of threats we face in OT control systems or industrial threats. New devices along with new communication protocols like Distributed Network Protocol 3 (DNP3) are being developed specifically for communications between various types of data acquisition and control equipment. They are beginning to play a crucial role in SCADA applications by offering more robust, efficient, interoperable, and secure communications.
Along with network segmentation, network management is also a crucial component of the security of your data. The idea is to manage and monitor the access of the network, traffic payload content (destination, source, type), minimize disruption of your data collection, maintain a standard of high performance, and avoid security issues. With a well-managed network, we can monitor the devices that have access to our network using numerous filtering techniques, monitor and maintain performance, and potentially catch issues before they can affect our network. Network management also allows us to get a jumpstart on redundancy by using a redundant configuration as well. More detail on this can be found in the next section.
“Humans continue to be the weakest link in information security. Whether deliberate or accidental, the actions of employees can quickly destroy a company. Organizations must keep this in mind when creating information security policies and while implementing safeguards.” - Rachel Holdgrafer
 While much of the security component has focused on the hardware and network elements, there is also a need to secure and monitor user access and interaction. With an ever-growing list of cyber threats, restricting access and limiting user interactions has never been more important. This limited interaction allows us to maintain integrity throughout our entire process. Strong password policies with two-factor authentication (when available) should be used to restrict user access and verify identification. Direct interaction to the data server should be limited to only necessary services to protect transactional data with as much interaction as possible relegated to the data warehouse. Unused ports on machines and switches should be disabled and universal serial bus (USB) or external device use should be limited and monitored.
While much of the security component has focused on the hardware and network elements, there is also a need to secure and monitor user access and interaction. With an ever-growing list of cyber threats, restricting access and limiting user interactions has never been more important. This limited interaction allows us to maintain integrity throughout our entire process. Strong password policies with two-factor authentication (when available) should be used to restrict user access and verify identification. Direct interaction to the data server should be limited to only necessary services to protect transactional data with as much interaction as possible relegated to the data warehouse. Unused ports on machines and switches should be disabled and universal serial bus (USB) or external device use should be limited and monitored.
With much of the SCADA or industrial control systems (ICS) running on legacy software and platforms, they may lack sufficient security for our purposes and should be segmented from the network as much as possible while allowing us to maintain the connection. There are solutions that can add security to these types of sites, like the Hirschmann Xenon Tofino industrial firewall, which adds a zone-level layer of security.
For applications and industries that are concerned with proprietary data or confidentiality, encryption should be considered with storage and transportation. Different methods in which we can encrypt our data storage include transparent data encryption, symmetric encryption with a set session key (advanced encryption standard [AES]-128 or AES-256; staying away from Rivest Cipher 4 [RC4]-128, which is considered broken) certificates as well as asymmetric encryption to securely exchange session keys. Using cryptographic-like presentation layer security such as secure sockets layer (SSL) or transport layer security (TLS) that authenticate data transfer between servers or systems provides endpoint encryption systems that prevent unauthorized access. We can also protect against web application attacks by using stored procedures to obfuscate our queries and table/database structures as well as protect against SQL injection attacks.
As we can see, the security component is quite complex and spans the gamut of our entire system from the devices providing the data to the applications used to retrieve and interact with our data. We can and should spend a significant amount of time during the design and implementation of our system focusing on security in detail.
To summarize:
- Immediately changing the default configuration of our devices allows us device-level protection against malicious attacks and protection of our raw data sources.
- IT/OT segmentation is a primary concern of security and can be achieved using a variety of network configurations, including firewall rules, dual-home host, and remote access servers, allowing us to reduce the possibility of system compromise.
- Network management allows us to monitor and maintain access to network resources, monitor network performance, and avoid security issues.
- User access and interaction should be monitored and restricted using strong passwords and two-factor authentication. Unused ports and network interfaces on devices should be disabled and we should have policies regarding external devices.
- Data/communication encryption can be used to secure data storage for sensitive or proprietary information as well as in data transportation and presentation.
- Using methods like stored procedures, we can protect against SQL injections.
“Experts often possess more data than judgment.” - Colin Powell
DATA RETENTION
The first thing we need to consider when forming data retention policies is a destination for the data. There are many options for database selection, but we should keep a few things in mind when making the selection, such as what type of database will we use (Microsoft Access, SQL, NoSQL, PostgreSQL, etc.; with SCADA application data generally requiring a more rigid database structure, we would typically select a SQL or PostgreSQL type database over a NoSQL type). What is the size, speed, and memory limits of the database (which can be a primary metric we monitor)? How is the database managed and by whom (this has traditionally been handled by IT)? What are the native capabilities for monitoring, security, redundancy, and retrieval? How will we communicate with the database? Does our database reside on its own machine or within our application server? In the case of an existing ICS system, we need to choose a database that is compatible and can communicate. Once we have selected a database, we can determine the methods of transferring data to it.
While most SCADA systems have data logging capabilities built in that have pre-defined table structures and handle the transfer of data, the ways in which these tables are structured or indexed (or not indexed) may not work for our needs, which is a factor that should be considered. The formats of these tables may also hinder our ability to run queries at the required speed to retrieve information and may need to be modified. The methods and policies regarding data retention will vary from industry to industry depending on regulatory needs, engineering and process needs, confidentiality agreements as well as other factors. While our retention needs may vary, there are a few best practices we can follow regardless of the needs of the data itself.
A good retention policy will outline what type of data we need to store, why the data is being stored, how long the records are kept, which people or applications have access to the data, how they will interface with the data, and how transactional data is protected along with how we will make exceptions to our policies in case of lawsuits or other disruptions.
Assuming a retention policy development team is already in place (if not, now would be a good time to form one), then the first task in constructing our retention policies is the selection and classification of data. We need to identify the important data and define the sensitivity and purpose of the data. What data do we need to retain? What is the data used for? Is the data of a sensitive or proprietary nature, and does it need to be encrypted? Our goal is to categorize various information assets based on the contents of the data and the audience to which it will be delivered and tag them as such.
Our classification policy should outline if the data is public and may be freely disclosed to the public (i.e., if it is internal data and has low security but is not meant for public disclosure, or if it is restricted and a breach could negatively impact operations or can create a risk to the organization). We also need to determine who can modify, delete, or move the data and how to track and audit the changes.
We need to keep in mind that SCADA data will typically have a different retention lifetime than that of IT or business data, as well as different sensitivity and security needs. While some data may be allowed to expire after a few minutes, we may need to retain other data for months or years depending on the purpose. There are cases where operational data will be used to update master plans, in rehabilitating or updating existing facilities, or in research for design and process development or improvement. In these cases, the data may not need to be as granular, but may be required to be stored for longer periods of time. In some cases, it may not be feasible or operationally efficient to store years’ worth of data in a single database. The larger the database gets, the longer it takes to retrieve data and run queries. Having archiving as part of retention policies allows us to deal with those issues whilst maintaining compliance. Our archiving policies allow us to free up application space, improve reporting and application performance, reduce storage costs, and reduce litigation exposure.
The second part of our retention policy should be compliance, which is a continual and ongoing process. Compliance policies ensure that our data retention adheres to government, business, industry, or agency rules as well as regulatory requirements. For instance, the North American Electric Reliability Corporation (NERC) instructs entities to maintain data for an entire compliance verification period. Meaning, the data collected must be retained for the whole 3- to 6-year auditing period. These compliance regulations will vary throughout different industries as well as geographical locations. We would first determine our regulatory agency/agencies to obtain their specific compliance frameworks and requirements. At some point, the data we are retaining will exceed our required data retention period and lose its useful value. It is at this point that we will need a data deletion and purge policy. Our deletion and purge policy is a supplementation to our retention policy and should include our archiving policies.
Most data has a finite life and should be disposed of once the retention, archival, legal, and regulatory requirements have been met. This lifecycle management should be performed systematically and within the bounds of our retention policy framework. We must be able to adapt to changes in retention policies (for example, changes in the regulatory framework regarding data collection interval requirements or data classification changes). These policies rely heavily on our data protection procedures to maintain the integrity of the data during its lifetime. For this integrity to remain trustworthy, the data should be stored in a manner that is immutable, meaning we can be sure the data has not been changed throughout its lifecycle. Once the data has reached the end of its lifecycle, it must be disposed of with as much care as it has been retained, as this is often a threat actor’s easiest means of data theft. Setting expiration dates and automating the deletion of data allows us to maintain a sound and consistent deletion policy as well as decrease storage and costs. We should always set a date or time retention range after which data should be archived as well.
We can use automated maintenance plans that allow us to perform tasks like rebuilding indexes, purging history, performing backups, clearing cached files, and other functions. All these tasks will help us maintain the speed of retrieval and integrity of our data. This automation also reduces the potential for human error in data maintenance. By automating these services, we can generally guarantee that the functions will run the same way every time. For instance, if we have a delete query to purge data beyond a certain date, we can be assured that a person is not going to accidentally use a less than (<) symbol rather than a greater than (>) symbol, potentially deleting data that we are required to retain rather than data that has expired, per our retention policies.
In the age of seemingly unending memory and storage, it is tempting to hoard data, and this is an urge we need to resist. Hoarding data will cause a decrease in available storage and an increase in associated costs. Retain only the data that is required and do not be afraid to delete or archive it.
“Data are just summaries of thousands of stories—tell a few of those stories to help make the data meaningful.” - Dan Heath
RETRIEVAL
With all this work to monitor, collect, secure, and retain data, we should not forget the purpose in doing so. We are collecting and maintaining data to be used. If we are not using the data, or do not see a future use for it, then there is no purpose in collecting it. A few things we need to decide in the retrieval and presentation of our data are who will have access to the data, how will we provide it, and how will we present it?
Our goal is to harness insights from the collected data. While we can gain a modicum of insight from data alone, a good presentation exponentially and immediately increases our ability to disseminate and analyze it. We are taking the data and turning it into information that can be consumed in a more viable and visual fashion. To make this a reality, we need to be working with reliable and quality data.
The retrieval process is directly affected by our security and data retention policies. We do not want direct interaction with our transactional data, as it opens us up to potential security issues as well as accidental deletion or modification of data that we want to remain immutable. During the retrieval and delivery of data, we can potentially open ourselves up to SQL injections, hence the recommendations for using encryption and stored procedures as part of our security policy. Using stored procedures also allows us to retrieve and present data at a faster rate, reduce network traffic, and avoid potential security issues. While the monitoring and security components have enabled us to ensure our transactional data is reliable and usable, and our retention policies make sure the data retrieved from our transactional server is secure and auditable, there is still the possibility of corruption during retrieval and delivery.
Even with the data in a data warehouse and our transactional data protected, we still need to restrict direct interaction with our raw data. Using views or virtual tables allows us to do just that.
A view is the result set of a stored query on the dataset. It is basically a predefined query that retrieves a dataset from our raw data and creates a virtual table with the result that our end-user can interact with without affecting our raw data. This also gives us an opportunity to increase the speed at which we deliver data. By creating views that serve only the data that is necessary for the current task, we reduce the need to iterate through every row in the table. Using set-based operations will perform faster in almost every case and allow us to simplify the code.
“Redundancy is ambiguous because it seems like a waste if nothing unusual happens. Except that something unusual happens—usually.” - Nassim Nicholas Taleb
REDUNDANCY
The redundancy of our data begins at the instrumentation and OT assets (e.g., PLC, remote terminal unit [RTU], etc.). This is where we begin our data value (data point) redundancy. The goal of our data value redundancy is to maintain a reliable value that is accessible for retrieval in the case of a data transfer failure. Beyond the point of the data value redundancy, we get into database and data file redundancy, discussed further below.
Understandably, it is not generally cost-effective to maintain two complete systems for every data point (although for maximum redundancy, this is ideal). For example, if we have a PH transducer communicating to a transmitter that is providing a value to your SCADA system, that edge device (the PH system) may be a single point of failure. If the probe fails, the data from the failed device is no longer reliable or quality data based on our standards. At that level of our system (the device level), this may be an acceptable failure as long as we have a spare transducer or transmitter on hand. Our monitoring system should have alerted us to the failure and allowed us time to correct the issue before it caused us to violate our data policies. Beyond the device level is where we can really begin to implement our redundancy.
Many devices that provide regulatory values have built-in or expandable storage. For example, a Hach SC200 has a secure digital (SD) card slot that allows onboard storage transfer of around 30 days’ worth of data. Assuming your transducer maintains reliability, this is a great point for redundancy of quality data in the case of a network or SCADA device failure. We can also use independent data logging devices to serve the same purpose as a low-cost device level redundancy solution.
Beyond the device level redundancy, we can use a store and forward system in the case of a database or data transfer failure. This generally requires an array of values at the controller level and timed interval data snapshots. For instance, we could be required to log a value every 15 minutes. To store a days’ worth of data, this would require an array of 96 data points.
In this example of an Allen Bradley Logix system, we've built a data structure that includes an index and value array and another structure that includes an index and a timestamp.

 The logic in the controller contains a timer that loads our data, index, and timestamp values using a first in, first out (FIFO) load (FFL) instruction. We use the same index value for each data point and timestamp logged. This allows us to know that the value at index 1 was logged with the timestamp at index 1.
The logic in the controller contains a timer that loads our data, index, and timestamp values using a first in, first out (FIFO) load (FFL) instruction. We use the same index value for each data point and timestamp logged. This allows us to know that the value at index 1 was logged with the timestamp at index 1.
 While the specific programming methods used in this controller may not work across all controllers, the idea is the same and most should have functions that will allow you to implement, store, and forward functions. We can then transfer this data as soon as we resolve our data transfer or database issues.
While the specific programming methods used in this controller may not work across all controllers, the idea is the same and most should have functions that will allow you to implement, store, and forward functions. We can then transfer this data as soon as we resolve our data transfer or database issues.
The next layer of data value redundancy would be something like a historian module. There are many manufacturers of historian modules, but they all achieve the same goal. The historian can collect data from multiple controllers at very high speeds. The memory on these historian modules will vary but generally would be 1 gigabyte (GB) and up. In a test case historian, an Allen Bradley 1756-HIST1G, 1,000 double integer points require a total memory of 61 megabytes (MB) (this memory includes device configuration and archive files) of the 1,024MB available. This allows us to store one months’ worth of all regulatory data points.
 After designing and configuring our data value redundancy, we can start to construct our database redundancy policies. Now, the methods used will depend on your specific database, but the concepts should apply regardless of the type of database you choose. One of the first steps to designing our database redundancy policies is to determine how much data we can lose and still maintain compliance, as this will determine our differential backup strategy.
After designing and configuring our data value redundancy, we can start to construct our database redundancy policies. Now, the methods used will depend on your specific database, but the concepts should apply regardless of the type of database you choose. One of the first steps to designing our database redundancy policies is to determine how much data we can lose and still maintain compliance, as this will determine our differential backup strategy.
Let's say you are required to maintain data in 15-minute intervals. This means we can lose up to 14 minutes’ worth of data without violating regulatory policies; if we lose that 15th minute, we have violated. In this case, we need to do a differential backup every 15 minutes. In the case of a SQL server, this would require us to backup our transaction logs every 15 minutes or perform a differential backup at the same interval. The transaction log in a SQL server is a log that records every transaction made to the SQL server database and is the most important component of the database when it comes to disaster recovery, as long as the file integrity is maintained. Every time the database is modified (a transaction occurrence), a log record is written to the transaction log. These logs are a recoverable snapshot of the last 15 minutes of data transactions. We do need to keep in mind that you cannot restore a transaction log without a previous full backup.
Our transaction logs should be backed up in the required intervals between the full and differential backups to allow for maximum data resilience. The full backup requires quite a bit of space as it is the size of the entire database. Full backup files, as well as transaction log and differential backups, should be disposed of based on our data retention policies, as they are not needed. Transaction logs, while they do not require as much space, can still consume storage if not managed properly, as we are generating them at a much faster rate than full or differential backups. Typically, we can dispose of the transaction log once the data is fully committed to the database.
In the following scenario, data loss occurs at 1:40am, so the changes made within the period of 1:39am and 1:50am will be lost. In this circumstance, we can restore our full backup at 12:00am, the differential backup at 1:00am, and the transaction log backups between 1:00am and 1:30am. The transaction log backup at 1:45am will allow us to roll back to as far as 1:39am, minimizing the data loss to an acceptable range. Our monitoring system should have alerted us to a data interval logging error in time to correct the issue.
 Along with our database backup policies, we can also run a less intensive, file server-based database such as Microsoft Access to maintain data. These types of databases have low programming or technical requirements and make excellent redundancy for the primary database. These databases would typically hold no more than a month of data to reduce storage costs. Ideally, the file server-based system will run on independent services (or engines such as the Access Database Engine). This allows for a failure of the services or engine running your primary database, while allowing us to continue logging to the secondary database. Going above and beyond in redundancy, we could have a stored procedure or script that runs to export an amount of data to a flat .CSV file on an off-site or network-attached file server (NAS). If for some reason all our other database redundancy fails (i.e., a server crash between full and differential backups), this allows us to retain and recover the lost data. For example, the following query runs a stored procedure to collect the data for the week and checks if a folder for the month exists. If it doesn’t exist, it creates it, creates a .CSV out of the data retrieved, and puts it in the folder for the month, adding the date the file was generated to the file name.
Along with our database backup policies, we can also run a less intensive, file server-based database such as Microsoft Access to maintain data. These types of databases have low programming or technical requirements and make excellent redundancy for the primary database. These databases would typically hold no more than a month of data to reduce storage costs. Ideally, the file server-based system will run on independent services (or engines such as the Access Database Engine). This allows for a failure of the services or engine running your primary database, while allowing us to continue logging to the secondary database. Going above and beyond in redundancy, we could have a stored procedure or script that runs to export an amount of data to a flat .CSV file on an off-site or network-attached file server (NAS). If for some reason all our other database redundancy fails (i.e., a server crash between full and differential backups), this allows us to retain and recover the lost data. For example, the following query runs a stored procedure to collect the data for the week and checks if a folder for the month exists. If it doesn’t exist, it creates it, creates a .CSV out of the data retrieved, and puts it in the folder for the month, adding the date the file was generated to the file name.
 We could use something like the 3-2-1 backup rule, which states:
We could use something like the 3-2-1 backup rule, which states:
3) Create one primary backup and two copies of your data,
2) Save your backups to two different types of media, and,
1) Keep at least one backup file off-site as a general guideline, and try to improve upon it.
We should have multiple locations for backup file destinations. Our initial backup file would reside on the database server, which allows us to recover and restore data in the case of a network outage. Once the backup is complete, multiple copies of the files should be made and copied to an off-site storage location (or ideally several different locations) to allow for recovery in the case of a catastrophic database system failure. We can also use something like an external hard drive, tape, rotated USB drives, or cloud solutions to allow copies on separate types of media.
Our complete redundancy from the device level to database would resemble something like the flow chart below:
 Now that we have redundancy of our database/data files, we need to ensure that our database/application servers maintain availability. This is typically determined by economic factors more than anything, as keeping a secondary server may double your application and licensing costs depending on your system. Ideally, you will have a redundant server that contains an exact replication of your primary server.
Now that we have redundancy of our database/data files, we need to ensure that our database/application servers maintain availability. This is typically determined by economic factors more than anything, as keeping a secondary server may double your application and licensing costs depending on your system. Ideally, you will have a redundant server that contains an exact replication of your primary server.
There are a few different trains of thought as far as the connectivity of these redundant servers. While maintaining the server connection to the network allows you to automate the replication, this also leaves your server open to the same attacks that take down your primary server. An operator plugs in an infected USB into an enabled port with a self-replicating payload that travels throughout your network, and you may lose your primary and secondary server.
For this reason, a manual replication policy with an air-gapped secondary server is a more viable solution. This air gap protects you from any transient virus that may depend on the host maintaining connectivity and availability. Once this host is removed from the network and you've switched to your redundant backup, you have reduced downtime and can investigate and correct the issue with the primary server.
This is also a good practice for preventing a ransomware situation. Your primary server can get hit with a ransomware attack and your air-gapped secondary server will be protected, giving you the ability to failover, rebuild your primary server, and avoid paying the ransom. Now, depending on your acceptable range of downtime, this may not be a viable solution as it requires:
1) More manhours making sure your secondary server replication is continually updated, and,
2) Reduces your ability to automatically failover to the secondary server, thus increasing your downtime.
In this case, we could do something like keeping the secondary server off the domain, disabling all remote access capabilities, and adding a unique local admin password. There should be no access to the administrative shares if domain credentials are breached. While this is not an air gap, it does allow us to effectively restrict access through network resources.
Along with redundancy in data files and adding redundant server hardware, we need to make sure we have our server image backup policies designed in a similar fashion. While we probably do not need 15-minute incremental backups of our server itself, we should have regular full and differential backups. Your backup policy could look something like a monthly full image backup, and a weekly (or daily depending on the frequency of changes) differential backups.
With all our backup strategies in place for our database/data files as well as our servers, it would be remiss of us not to add resilience to our network. While we have covered our network design, our network topology allows us to add an additional layer of redundancy to our system. While this is a very complex subject, we will go over the basics of the most used redundant topologies.
While network redundancy does not typically add redundancy to end devices, as that redundancy would be provided by the device itself (think dual network interface controller [NIC] cards in a server with an application mechanism to facilitate failover and prevent loopbacks), it is responsible for the availability of the entire topology (depending on the topology you choose; many IIoT devices now support redundant ring topologies).
The primary consideration when choosing a network topology is recovery time. While having a fast stated recovery time is important, there are other factors that determine your actual recovery time, such as how much traffic is on the network, how many devices exist on the network (more devices equal more learned media access control [MAC] addresses), where the failure is in relation to the redundancy manager, transport layer protocols, and so on.
There are many proprietary protocols that exist for network redundancy, but we will only be covering the most common standardized protocols. Rapid spanning tree protocol (RSTP) is the primary go-to redundancy topology throughout most of the enterprise world. RSTP creates a resilient mesh network allowing greater than two paths between network infrastructure devices. While being very flexible, it does come at the cost of lower recovery speeds and may not be the best option for mission-critical or industrial networks. It is easy to implement, but requires quite a bit of fine-tuning to improve recovery speeds.

Redundant ring topology is the methodology of choice in the industrial world. Even though ring topologies only allow two paths out of each switch, they increase recovery time significantly compared to other redundant topologies. There are countless proprietary ring protocols, such as X-Ring, resilient ethernet protocol (REP), N-Ring, etc. Here, we will focus on two non-proprietary standardized protocols.
Device level ring (DLR) protocol allows a realized recovery time of less than 3 milliseconds and provides a nearly “bumpless” failover. In this case, if your requested packet interval (RPI) is less than 3 milliseconds, you will not notice a network drop; it would appear as nothing ever happened, save for the ring fault notification. DLR is part of the Ethernet/IP standard and is supported by many current Ethernet/IP IIoT devices which allows us to include our edge devices in the redundant network. DLR allows network faults and errors to be quickly remedied. A DLR network includes at least one node that acts as a ring supervisor and any number of normal ring nodes. It is assumed that all the ring nodes have at least two ethernet ports and incorporate embedded switch technology.
Media redundancy protocol (MRP), originally the HiPER-ring protocol and developed by Hirschmann, is now standardized as part of the IEC 62439-3 industrial communication network standard and can guarantee a maximum recovery time of 200 milliseconds in an application with a maximum of 50 nodes. MRP redundancy failover is controlled by the ring manager (a Media Redundancy Manager), which blocks a port until it detects a failure in the ring. In that case, the port becomes unblocked and moves to a forwarding status.
 Regardless of the topologies and protocols used, network redundancy adds another layer of redundancy to facilitate data collection and transfer and adds to the resiliency of the entire system as a whole.
Regardless of the topologies and protocols used, network redundancy adds another layer of redundancy to facilitate data collection and transfer and adds to the resiliency of the entire system as a whole.
To summarize:
- Data retention is the main purpose of what we are doing after monitoring and security. Our database selection will influence data availability and speed.
- For SCADA purposes, SQL or PostgreSQL allows us a database with a more rigid structure. We need to make sure database selection is compatible with our existing system.
- Our retention policy team should construct, maintain, and update our retention policies.
- Most data has a finite life and should be disposed of with care. This also allows us to reduce storage costs.
- Automated tasks allow us to maintain data integrity, speed, and optimize retrieval.
- Stored procedures allow us to obfuscate database and table structures, protecting us from SQL injection while speeding up our delivery of data.
- Using views or virtual tables allows us to protect our raw data while also increasing the speed of delivery. Our first level of redundancy resides at the device level.
- While having redundant value systems is ideal, it may not be economically feasible. Although with IIoT devices we can leverage onboard storage capabilities when available.
- At the controller/programmatic level, we can leverage, store, and forward techniques as well as historian hardware.
- Beyond our data value redundancy, we should add redundancy to our database structure. We can do this by constructing thorough database backup policies which include full, differential, and transaction log backups.
- Using less intensive, file server-based databases such as Microsoft Access allows us database redundancy that runs on independent services or database engines. Improving upon the 3-2-1 backup recommendations, we should have multiple backups of data and files in different locations as well as on multiple types of media.
- We can also take advantage of custom scripting or queries to export data to a flat file in an off-site location(s).
- An air-gapped redundant server is an ideal level of server hardware redundancy. When this is not feasible, we can remove the server from the domain, disable remote access, and have a local administrator account and password.
- Our server image should be included in our backup policies.
- Our network topology can allow us to add an additional layer of redundancy to our system. This can be done using many different topology configurations, with the most common in the industrial world being mesh utilizing RSTP and ring using MRP or DLR.
We can see through this article that even though the individual components outlined can and do exist independently, they work as a whole to improve our ability to reliably collect, transmit, deliver, and present quality and usable data. By removing any one of the components, we drastically reduce the resiliency of our system and expose ourselves to the potential negative consequences that come with inaccurate, unreliable, or missing data.
